



یک پیشنهاد برای دور زدن کمبود دادههای پنل
نامها حاوی اطلاعات اقتصادی و اجتماعی هستند
این روش جریان اصلی علم اقتصاد همان چیزی است که اقتصاددانها و اقتصادخوانها از آن با عنوان اقتصادسنجی یاد میکنند. اقتصادسنجی در واقع استفاده از علم آمار برای جمعآوری و تحلیل دادهها است. این روش که در ظاهر رنگوبوی ایدئولوژیک ندارد، در باطن خود، بر پایه یک فهم کموبیش ایدئولوژیک شکل گرفتهاست؛ اینکه جهان حاوی یک نظم پیوسته است. به بیانی دیگر، در جهانی که ما در آن زندگی میکنیم، نوعی امر کلی وجود دارد که راه کشف آن، مطالعه پیوسته و مکرر امور جزئی است. ما آنقدر باید به مطالعه امور جزئی بپردازیم تا شاید روزی بتوانیم به کشف امر کلی نائل شویم. به این ترتیب، امر جزئی در این روش حائز اهمیت ویژه میشود. آنچنانکه هر امر جزئی توان آن را دارد تا هر نوع تلقی از امر کلی را زیر سوال ببرد. لکن، در این میان یک مشکل جدی وجود دارد.
در واقع، جدای از نقدهای گاه کوبنده مخالفان اقتصادسنجی به این روش جریان اصلی علم اقتصاد، این روش از یک مشکل اساسی که خود نیز به آن معترف است، رنج میبرد. این مشکل از این قرار است که مطابق این روش، ابتدا باید دادهای باشد تا سپس امر تحلیل دادهها آغاز شود. واقعیت آن است که وجود داشتن دادهها یا دسترسی به آنها همواره ممکن نیست. بهعنوان یک مثال ساده، ما برای تحلیل روندهای اقتصادی ایران در دوران قاجار یا به کل داده موثقی نداریم یا با کمبود داده مواجه هستیم. این مشکل کمبود داده یا نبود آن، گاه به زمانهای حاضر هم میرسد. اساسا یکی از مشکلات کشورهای در حال توسعه کمبود داده یا عدم دسترسی به دادههای موجود است. به این ترتیب، در اینجا یک پرسش مهم به وجود میآید؛ زمانی که ما به دادهها دسترسی نداریم، چه باید بکنیم؟ آیا اینجا پایان اقتصادسنجی و روش جریان اصلی علم اقتصاد است؟ پاسخ سنجیکاران به این پرسش، یک « نه» قاطع است.
بهعنوان مثال، یکی از نیازهای جدی سنجیکاران برای تحلیل روندهای اقتصادی، دادههایی هستند به نام دادههای پنل یا همان Panel Data. با حضور این دادهها، سنجیکارها میتوانند وضعیت افراد معینی (شرکت، شهر و هر واحد دیگر) را در طول زمان رصد کنند و به این ترتیب، تغییر وضعیت آنها را متناسب با تغییر متغیر مورد نظر خودشان را رصد و نتایج قابل استناد و بدون سوگیری را استنتاج کنند. لکن، یکی از بزرگترین مشکلات موجود در کشورهای در حال توسعه نبود این دادههای پنل است. درست به همین دلیل، اهالی علم اقتصاد در کشورهای در حال توسعه با بنبستهای مطالعاتی مواجه میشوند. حال برای حل این مشکل چه باید کرد؟ باید پرسش را رها کرد و منتظر ماند تا دادههای پنل برای سوال فراهم شود یا نه؛ میتوان با انجام یکسری حرکات هوشمندانه، نوعی ارتباط خلق کرد. همان چیزی که سنجیکاران از آن با عنوان Pseudo Panel یا نوعی «شبه ارتباط» یاد میکنند. عملی که منجی اقتصاددانان در زمان کمبود دادهها میشود و کمک میکند تا پاسخهای هر چند نادقیق؛ اما، کارآمد را برای پرسشهای خود ارائه کنند. یادداشت امروز ما بنا دارد تا به معرفی یکی از همین راههای برقراری شبهارتباطات در زمان نبود دادههای پنل بپردازد؛ راهکاری که میتواند به محققان کشور کمک بسیاری برای پیگیری پاسخ پرسشهای خودشان کند.
یک خلاقیت شگفتانگیز
کلودیا اولیوتی و دانیل پاسرمن دو اقتصاددان معروف در حوزه نیروی کار، در سال2015 میلادی مقالهای با عنوان «تحرک بیننسلی در ایالات متحده آمریکا از سال 1850 تا 1940» (Intergenerational Mobility in the United States, 1850–1940) را منتشر کردند که در آن به دنبال محاسبه میزان کشش درآمدی بیننسلی میان پدران و فرزندان در آمریکای سالهای 1850 تا 1940 بودند. آنها برای انجام این کار با یک مشکل مهم مواجه بودند؛ این مشکل نیز چیزی نبود جز کمبود دادههای پنل. آنها بر اساس دادههای موجود برای برقراری ارتباط دقیق میان پدران و فرزندان ناتوان بودند. این مشکل درخصوص دختران شکل ویژهتری به خود میگرفت؛ زیرا با تغییر نام خانوادگی دختران پس از ازدواج، بهطور کامل ارتباط میان پدران و دختران در سرشماریهای جمعیتی از بین میرفت و در نتیجه، ردگیری افراد با بنبست مواجه میشد.
بنابراین، تخمین کششهای بیننسلی و به دنبال آن برآورد میزان تحرک بیننسلی یا همان جابهجایی طبقاتی برای آمریکای 1850 تا 1940 با مشکل کمبود دادههای پنل مواجه شده بود. آنها برای حل مشکل دست به دامان «شبهارتباطها» شدند. درواقع، همانطور که سنجیکاران بیان میکنند، زمانی که ما با کمبود دادههای پنل مواجه هستیم، میتوانیم از مدل شبهپنل یا همان Pseudo Panel استفاده کنیم. منطق این روش از این قرار است که ما چون به تکتک افراد و رصد کردن آنها در طول زمان دسترسی نداریم، واحد مطالعاتی خود را از افراد به گروه یا همان cohort تغییر میدهیم. درواقع، در اینجا ما باید هنر خلق گروه یا cohort داشته باشیم. ما باید گروههای خودمان را طوری طراحی کنیم که افراد موجود در هر گروه تقریبا یکسان به نظر برسند. در این حالت، دیگر ما به دنبال رصد کردن افراد در طول زمان نیستیم، بلکه به دنبال رصد کردن گروهها در طول زمان هستیم. گروههایی که افراد داخل آن گویی آنقدر مشابه یکدیگرند که همگی یکسان تلقی میشوند.
همانطور که متوجه شدید، خلق یا کشف این گروهها نوعی هنر است. کاری سخت که باید بتواند نقش نمایندگی خود را به خوبی اجرا کند. حال وقت آن رسیده است که از هنر اولیوتی و پاسرمن در مقاله مذکورشان رونمایی کنیم. آنها برای تشکیل گروهبندیهای خود از یک فرض کلیدی استفاده کردند. فرض کلیدی آنها از این قرار بود که اسمهای کوچک افراد، چه پسران و چه دختران، حاوی اطلاعات کلیدی درخصوص وضعیت اقتصادی و اجتماعی آنها است. به بیان دیگر، آنها بیان کردند که هر اسمی نشاندهنده طبقه اقتصادی-اجتماعی آن فرد است. بهعنوان مثال، اگر اسم پسری ادوارد و اسم دختری ماریان باشد، آنها احتمالا از طبقه اقتصادی بالای جامعه هستند و پدران ثروتمندی دارند. همچنین اگر اسم پسری چارلی و اسم دختری نانسی باشد، آنها احتمالا از طبقه اقتصادی پایین جامعه هستند و پدران فقیری دارند.
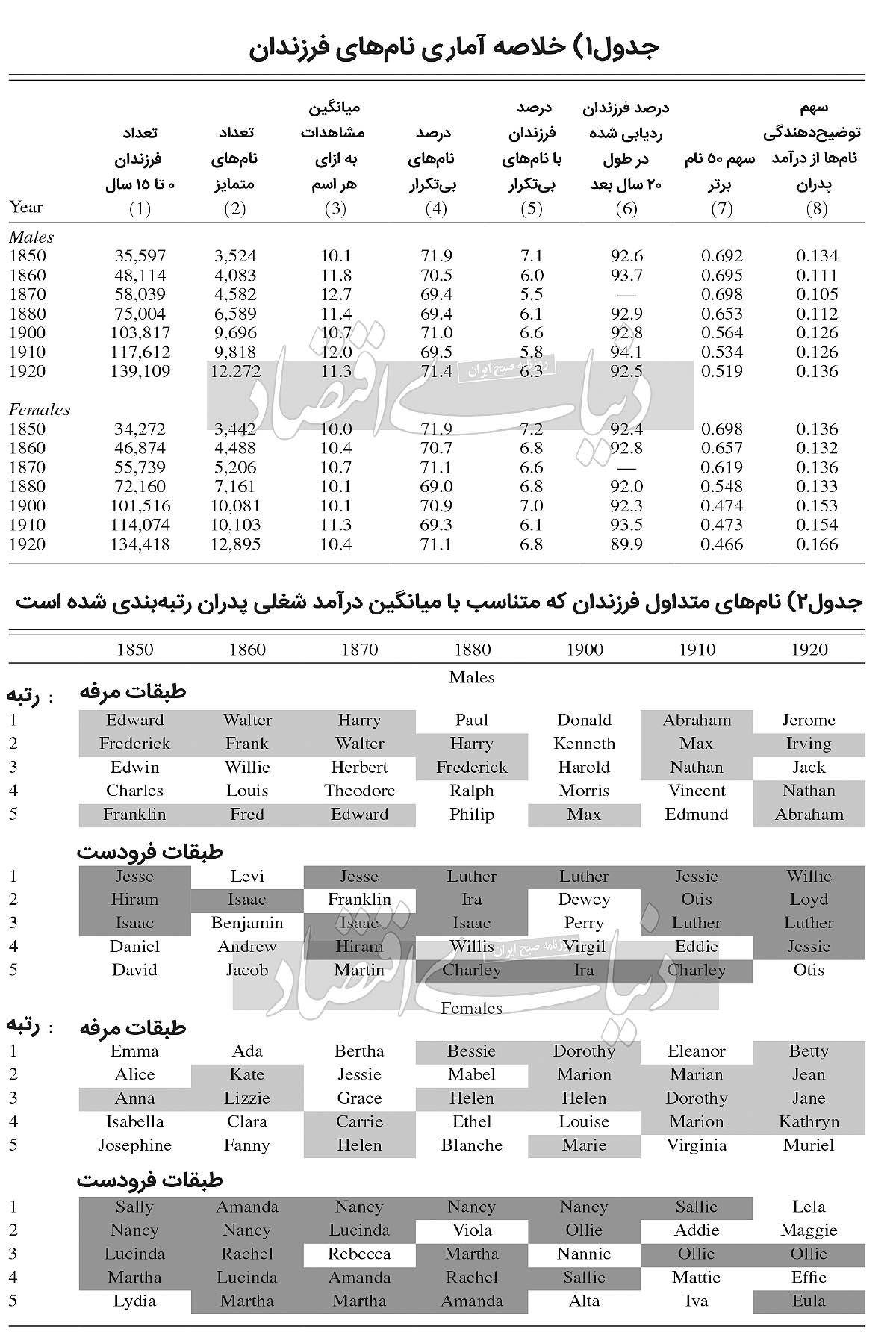
بنابراین، این دو اقتصاددان با این فرض گروهها یا همان cohortهای خود را بر مبنای اسمهای کوچک موجود در سرشماریها ساختند. آنها فرض کردند که افراد هر گروه که اسم کوچک یکسانی دارند، به یک وضعیت اقتصادی-اجتماعی خاصی تعلق دارند. حال اینکه آنها در ادامه این مقاله چگونه با این روش توانستند موفق به برآورد کششهای بیننسلی در آمریکا شوند، مساله یادداشت ما نیست، مساله یادداشت ما این است که آیا این فرض کلیدی درست است و ما از این طریق میتوانیم برای خود گروهها یا cohortهایی بسازیم یا خیر؟ زیرا اگر این فرض درست باشد، ما یک راه خلاقانه برای دور زدن کمبود دادههای پنل و خلق Pseudo Panelها بهدست آوردهایم.اولیوتی و پاسرمن برای انجام این کار یک معادله رگرسیون ساده زدند. آنها با تشکیل یکسری Dummy Variableها مبتنی بر اسامی فرزندان، درآمد پدران را بر نام فرزندان رگرس کردند. نتیجه، تایید فرضیه آنها بود. به بیان سادهتر، آنها به بررسی این مساله پرداختند که با تغییر نام کوچک فرزندان، آیا میزان درآمد پدران تغییر پیدا میکند یا خیر؟ نتیجه، از این قرار بود که با تغییر نام کوچک فرزندان، میزان درآمد پدران تغییر پیدا میکرد. همانطور که در ستون هشت جدول شماره1 مشاهده میکنید، تغییر نام کوچک فرزندان، در پسران 11 تا 13درصد از تغییر درآمد پدران را توضیح میدهد. همچنین، تغییر نام کوچک فرزندان در دختران نیز 13 تا 17درصد تغییر درآمد پدران را توضیح میدهد. این درصدها که در واقع به قول سنجیکاران میزان R2 مدل را نشان میدهد، شاید آنچنان زیاد نباشد؛ اما نشان میدهد که مدل آنها معنادار است و فرض آنها را مبنی بر اینکه اسامی کوچک نشانگر وضعیت طبقه اقتصادی-اجتماعی افراد است، تایید میکند.البته، بدیهی است که این میزان توضیحدهندگی مدل کم است. لکن، دستکم یک ادعای آنها درست است. همانطور که در جدول شماره2 مشاهده میکنید، ما برای پسران و دختران، 5نام پرکاربرد را هم برای طبقات بالای جامعه و هم برای طبقات پایین جامعه از دهه1850 تا دهه1920 را فهرست کردهایم. همانطور که برخی اسامی با رنگ خاکستری روشن (طبقات مرفه) و خاکستری تیره (طبقات فرودست) نشانگذاری شدهاند، به ما بیان میکنند که اسامی پرطرفدار چه در طبقات بالای اقتصادی و چه در طبقات پایین اقتصادی، در طول هفت دهه از نوعی تکرار و تداوم برخوردار بودند. به دیگر سخن، این مساله نشان میدهد که اسامی کوچک افراد دارای توزیع تصادفی نیستند. در نتیجه، این عدم توزیع تصادفی نشانگر وجود نوعی اطلاعات کلیدی در باطن این اسمها است.
جمعبندی
آنچه ما از مقاله اولیوتی و پاسرمن یاد گرفتیم، از این قرار بود که زمانی که به دادههای پنل دسترسی نداریم، برای ساخت گروههای لازم برای مدل Pseudo Panel خود برای دور زدن محدودیت دادهها، میتوان از اسامی کوچک افراد استفاده کرد. اسامی کوچک با عدم توزیع تصادفی مواجه هستند و میتوانند با تغییر خود، 11 تا 17درصد از تغییر درآمد پدران را توضیح دهند. در نتیجه، اسامی کوچک حاوی اطلاعاتی درخصوص وضعیت اقتصادی-اجتماعی افراد هستند. بنابراین، این فرض شاید به اقتصاددانان کشور ما نیز برای دور زدن محدودیت دادههای پنل کمک کند.
* منبع جدولها : مقاله «تحرک بیننسلی در ایالات متحده آمریکا از سال 1850 تا 1940» از کلودیا اولیوتی و دانیل پاسرمن.






