



داروی یادگیری ماشین برای مسائل اقتصادی

تصور کنید سیستمها بدون اینکه برای هر جزئیات برنامهریزی شده باشند، به صورت مستقل از تجربیات خود بیاموزند و کارهایی مانند تشخیص تصویر، پردازش زبان یا تحلیل دادههای اقتصادی مانند تورم را انجام دهند. این توانایی خیرهکننده است، اما چطور میتوان آن را به کار گرفت؟ بیایید به مراحل یادگیری ماشین نگاهی بیندازیم.
شش مرحله یادگیری ماشین
برای فهم بهتر این فناوری، مراحل کلیدی یادگیری ماشین را به زبان ساده و با مثال پیشبینی تورم توضیح میدهیم (Murphy, ۲۰۱۲).
۱.تعریف مساله(Problem Definition) : اولین قدم، تعریف مساله است. فکر کنید میخواهید بدانید که نرخ تورم در آینده چگونه تغییر میکند. پیشبینی این مساله به ما کمک میکند تا برنامهریزی بهتری برای سیاستهای اقتصادی داشته باشیم و تاثیر تصمیمات کلان اقتصادی را بهتر درک کنیم.
۲.جمعآوری دادهها(Data Collection) : برای هر تصمیم هوشمند، به دادههای مناسب نیاز داریم. در مثال تورم، دادههایی از قبیل نرخهای گذشته تورم، نرخ بهره، قیمت کالاها و شاخصهای اشتغال از منابع معتبر مانند بانکمرکزی یا صندوق بینالمللی پول جمعآوری میشوند. این دادهها پایه اصلی مدل یادگیری ماشین را تشکیل میدهند.
۳.پیشپردازش دادهها(Data Preprocessing) : دادهها به شکل خام قابل استفاده نیستند؛ آنها باید برای مدلهای یادگیری ماشین آمادهسازی شوند. مثلا برخی دادهها ممکن است گم شده باشند یا پرت باشند. در این مرحله دادهها تصحیح و نرمالسازی میشوند تا الگوریتمها بتوانند بهتر از آنها استفاده کنند. اگر دادهای گم شده باشد، میتوانیم با استفاده از اطلاعات مشابه، آن را تکمیل کنیم.
۴.انتخاب مدل(Model Selection) : حالا که دادهها آمادهاند، باید مدلی انتخاب کنیم که به بهترین شکل بتواند مساله را حل کند. مثلا برای پیشبینی تورم، مدل رگرسیون خطی میتواند گزینه خوبی باشد. انتخاب مدل به پیچیدگی مساله و میزان دادههای موجود بستگی دارد. این مرحله از اهمیت ویژهای برخوردار است، چرا که موفقیت در پیشبینی به انتخاب مدل مناسب وابسته است.
۵.آمـــوزش و ارزیــــابـــی مــــدل (Training & Evaluation the Model) : ابتدا مدل انتخابشده را با دادههای گذشته آموزش میدهیم تا یاد بگیرد چگونه براساس ویژگیهایی مانند قیمت کالاها و نرخ بهره، نرخ تورم را پیشبینی کند. سپس، برای ارزیابی عملکرد مدل، از دادههای آزمون استفاده میکنیم. بهعنوان مثال، فرض کنید که دادههای مربوط به ۱۰۰ماه گذشته را در اختیار داریم و آنها را به دو بخش تقسیم میکنیم: ۸۰ماه برای آموزش و ۲۰ماه برای ارزیابی (اعتبارسنجی). در مرحله آموزش، مدل با استفاده از دادههای آموزشی (۸۰ماه اول) بهتدریج الگوها و روابط بین متغیرها را یاد میگیرد. پس از این مرحله، مدل را آزمایش میکنیم تا ببینیم آیا میتواند نرخ تورم ۲۰ماه باقیمانده را بهدرستی پیشبینی کند یا خیر. در صورتی که نتایج پیشبینی مدل با دادههای واقعی فاصله زیادی داشته باشد، تغییرات لازم را در مدل اعمال میکنیم تا دقت و اثربخشی آن بهبود یابد.
۶.پیــــادهســـازی و بـــهبــود مــدل (Deployment and Improvement) : پس از آمادهسازی و ارزیابی مدل، مرحله پیادهسازی آغاز میشود. در این مرحله، مدل برای پیشبینی نرخ تورم آینده به کار گرفته میشود و از نتایج آن در فرآیندهای تصمیمگیری استفاده میشود. اما این پایان کار نیست؛ چرا که مدل نیازمند بهروزرسانی مداوم است تا دقت و اثربخشی خود را حفظ کند. فرض کنید از دادههای سالهای ۱۳۷۰ تا ۱۴۰۲ برای آموزش مدل استفاده کردهایم و مدل نرخ تورم سال ۱۴۰۳ را پیشبینی کرده است. حال، اگر به دلیل تغییرات عمده در وضعیت اقتصادی، این پیشبینی با نرخ تورم واقعی سال ۱۴۰۳ تفاوت قابلتوجهی داشته باشد، مدل باید با استفاده از دادههای جدید و بهروزرسانیشده دوباره آموزش ببیند. به این ترتیب، یادگیری ماشین بهطور مستمر خود را با شرایط و دادههای جدید تطبیق میدهد تا پیشبینیهای دقیقتر و بهروزتری ارائه دهد.
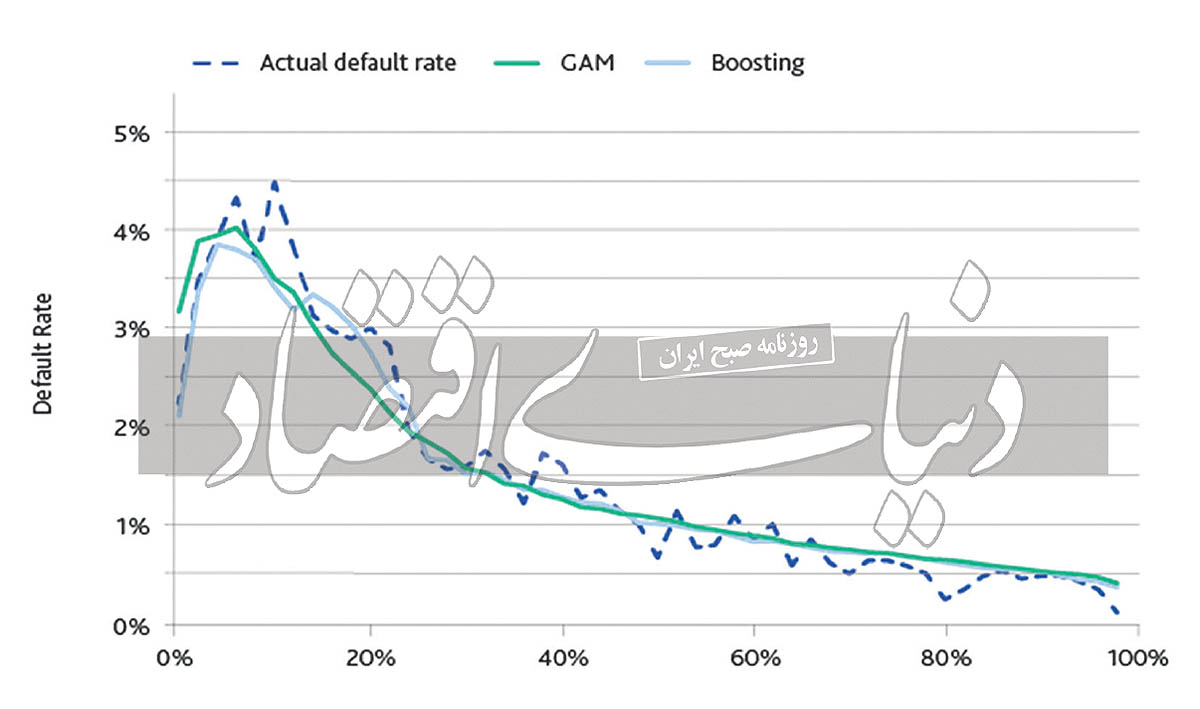
کاربرد یادگیری ماشین در اقتصاد
یادگیری ماشین بهطور گسترده برای تحلیل دادهها، پیشبینی روندها و بهینهسازی تصمیمات اقتصادی استفاده میشود. این فناوری فرصتی استثنایی برای بهبود فرآیندهای تصمیمگیری در اقتصاد فراهم کرده و باعث شده است بسیاری از چالشهای پیچیده با دقت و سرعت بیشتری مدیریت شوند. در اینجا به چند کاربرد عملی یادگیری ماشین در اقتصاد اشاره میکنیم.
1.پیشبینی تورم و نرخ بهره
الگوریتمهای یادگیری ماشین میتوانند برای پیشبینی متغیرهای کلان اقتصادی مانند تورم و نرخ بهره استفاده شوند. مثلا با استفاده از دادههای گذشته قیمت کالاها، نرخ بهره، تولید ناخالص داخلی(GDP) و سایر متغیرها، قادر به پیشبینی تغییرات آینده در نرخ تورم هستند. این نوع پیشبینیها به بانکهای مرکزی کمک میکنند تا سیاستهای پولی مناسبی تدوین کنند (Stock & Watson, 2016).
2.مدیریت ریسک مالی
در صنعت بانکداری و امور مالی، یادگیری ماشین برای مدیریت ریسکهای اعتباری به کار میرود. برای مثال، الگوریتمهای یادگیری ماشین به بانکها کمک میکنند مشتریانی را که ممکن است در پرداخت وامهای خود مشکل داشته باشند شناسایی کنند. این مدلها با تحلیل دادههای گذشته اعتباری، رفتار پرداخت و سایر دادههای مالی مشتریان، الگوهایی را شناسایی میکنند که میتواند احتمال عدمپرداخت را پیشبینی کند (Khandani et al., 2010).
3.تجزیه و تحلیل بورس
یادگیری ماشین به سرمایهگذاران و معاملهگران در تحلیل بازارهای مالی کمک میکند. الگوریتمهای مناسب میتوانند الگوهای موجود در قیمتهای سهام را شناسایی کنند و پیشبینیهای دقیقی در مورد روند آتی بازار ارائه دهند. بهعنوان مثال، الگوریتمهای یادگیری ماشین برای تحلیل اخبار اقتصادی و تاثیر آنها بر بازار سهام استفاده میشوند و به تصمیمگیران کمک میکنند تا استراتژیهای معاملاتی خود را بهینه کنند (Chen et al., 2017).
4.تحلیل رفتار مصرفکننده
شرکتها با استفاده از یادگیری ماشین، رفتار مصرفکنندگان را تحلیل میکنند تا استراتژیهای بازاریابی موثری ایجاد کنند.
بهعنوان مثال، مدلهای خوشهبندی میتوانند مشتریان را به دستههایی با ویژگیهای مشترک تقسیم کنند و این اطلاعات به شرکتها کمک میکند تا پیشنهادهای شخصیسازیشدهای به هر مشتری ارائه دهند. این تحلیلها به بهبود تجربه مشتری و افزایش فروش کمک میکنند (Hastie et al., 2009).
5.پیشبینی رشد اقتصادی
یادگیری ماشین میتواند برای پیشبینی رشد اقتصادی کشورها نیز استفاده شود. با استفاده از دادههای متغیرهای کلیدی اقتصادی مانند سرمایهگذاری، نرخ بهره، نرخ بیکاری و دادههای صادرات و واردات، مدلهای رگرسیونی و... میتوانند نرخ رشد اقتصادی را با دقت بیشتری پیشبینی کنند. این پیشبینیها به دولتها و سیاستگذاران کمک میکنند تا تصمیمات اقتصادی مناسبی اتخاذ کنند (Ng, 2018).
6.کاربرد در اقتصاد سلامت
یکی از حوزههای جذاب و نوین برای استفاده از یادگیری ماشین، اقتصاد سلامت و محیطزیست است. در حوزه سلامت، یادگیری ماشین میتواند به تحلیل هزینههای بهداشتی، پیشبینی نیازهای منابع پزشکی و بهبود تخصیص بودجه به حوزههای مختلف سلامت کمک کند. مثلا مدلهای یادگیری ماشین میتوانند دادههای بیماران، نرخهای بستری و استفاده از خدمات درمانی را تحلیل و به بیمارستانها و مراکز بهداشتی کمک کنند که خدمات خود را بهینه کنند و هزینهها را کاهش دهند. این ابزار به سیاستگذاران حوزه سلامت کمک میکند تا برنامههای موثرتری را برای تامین منابع و خدمات بهداشتی طراحی کنند (Obermeyer, Powers, & Vogeli, 2016). در حوزه محیطزیست، یادگیری ماشین میتواند برای تحلیل دادههای زیستمحیطی و پیشبینی تغییرات اقلیمی و بحرانهای محیطی به کار رود. مثلا با استفاده از دادههای ماهوارهای و سنسورهای زیستمحیطی، الگوریتمهای یادگیری ماشین میتوانند تغییرات دما، کیفیت هوا و آب و میزان انتشار گازهای گلخانهای را پیشبینی کنند. این اطلاعات به دولتها و سازمانهای مسوول محیطزیست کمک میکند تا سیاستهای مناسبی را برای حفاظت از محیطزیست و کاهش اثرات منفی تغییرات اقلیمی تدوین کنند (Williams, Brown, & Green, 2020) . همچنین، مدلهای یادگیری ماشین میتوانند به بهینهسازی مصرف انرژی و مدیریت منابع طبیعی کمک کنند تا در جهت پایداری و حفظ اکوسیستمها اقدامات موثری انجام شود.
7.مدلسازی زنجیره تامین و لجستیک
یادگیری ماشین همچنین در مدلسازی و بهینهسازی زنجیره تامین و لجستیک در اقتصاد به کار میرود. بهعنوان مثال، شرکتهای تولیدی میتوانند با تحلیل دادههای تقاضای مشتریان، به بهبود برنامهریزی تولید و انبارداری خود بپردازند و هزینهها را کاهش دهند (Choi et al., 2018).
چالشهای یادگیری ماشین و دلایل نداشتن پیشبینی دقیق
یادگیری ماشین بهعنوان ابزاری قدرتمند برای تحلیل دادهها و پیشبینی روندها استفاده میشود، اما همچنان چالشهای متعددی وجود دارند که دقت پیشبینیها را تحتتاثیر قرار میدهند. این چالشها با پیچیدگی دادهها، رفتار غیرقابل پیشبینی انسان و عوامل متعددی که بهسختی قابل مدلسازی هستند، مرتبطند. در اینجا به برخی از این چالشها و نحوه مواجهه با آنها میپردازیم.
1.غیرقابل پیشبینی بودن رفتار انسان
یکی از چالشهای بزرگ یادگیری ماشین، غیرقابل پیشبینی بودن رفتار انسان است. رفتار انسان تحتتاثیر عوامل اجتماعی، فرهنگی، روانی و حتی محیطی قرار دارد که بسیاری از آنها بهسختی میتوانند بهطور دقیق مدلسازی شوند. این موضوع بهویژه در پیشبینیهای اقتصادی و تحلیل رفتار مشتریان، چالشبرانگیز است. رفتار انسان میتواند بهطور ناگهانی تغییر کند و این تغییرات غیرمنتظره میتواند باعث کاهش دقت مدلهای یادگیری ماشین شود (Russell & Norvig, 2021).
2.دادههــای پــــرت و نـــامـــنـــظم (Data Noise and Outliers)
وجود دادههای پرت و نامنظم میتواند تاثیرات منفی جدی بر عملکرد مدلهای یادگیری ماشین داشته باشد. این دادههای غیرمعمول میتوانند به دلیل خطاهای انسانی یا مشکلات در جمعآوری دادهها ایجاد و باعث شوند مدل به سمت الگوهای نادرست سوق پیدا کند (Hastie et al., 2009).
3.محدودیت دادههای آموزشی
کیفیت و کمیت دادههای آموزشی (مرحله پنجم از ششمرحله گفتهشده در بخش اول) بهطور مستقیم بر کارآیی مدل تاثیر میگذارند. اگر دادهها ناکافی یا یکجانبه باشند، مدل نمیتواند بهخوبی تعمیم داده شود و رخدادهای جدید یا نوسانات اقتصادی را پیشبینی کند. برای مثال، اگر دادههای گذشته تنها شامل یک دوره زمانی خاص باشد، مدل نمیتواند بحرانهای ناگهانی مالی را بهدرستی پیشبینی کند (Bishop, 2006).
4.ســوگــیـری در دادههــا و مــدلها (Bias in Data and Models)
یکی دیگر از چالشهای یادگیری ماشین، وجود سوگیری در دادهها و مدلهاست. اگر دادههای آموزشی دارای سوگیری باشند، مدل نیز نتایج جانبدارانهای تولید خواهد کرد. بهعنوان مثال، اگر دادههای آموزشی بهگونهای جمعآوری شوند که تنها بخشی از جامعه یا الگوهای رفتاری خاص را نمایندگی کنند، مدل یادگیری ماشین ممکن است پیشبینیهای ناعادلانهای انجام دهد. این مشکل بهویژه در کاربردهای اجتماعی و اقتصادی میتواند نتایج نامطلوبی به همراه داشته باشد (Barocas, Hardt, & Narayanan, 2019).
روشهای مقابله با چالشهای یادگیری ماشین
بهمنظور مقابله با چالشهای مختلف یادگیری ماشین، میتوان از روشهای گوناگونی استفاده کرد که مبتنی بر آخرین تحقیقات در سطح جهان هستند. این روشها بهمنظور بهبود دقت، پایداری و انصاف مدلها پیشنهاد میشوند.
1.استفاده از دادههای متنوع و جامع
بهمنظور مقابله با مشکل محدودیت دادهها و سوگیری، باید از دادههای جامع و متنوع استفاده کرد که تمامی گروههای مختلف را پوشش دهند. جمعآوری دادههای نماینده و بررسی کیفیت آنها بهمنظور جلوگیری از سوگیریهای سیستماتیک میتواند به دقت بیشتر مدلها کمک کند (Binns, 2020).
2.فیلتر کردن دادههای پرت و نامنظم
بهمنظور مقابله با دادههای پرت و نامنظم، از تکنیکهای فیلتر کردن دادهها مانند استفاده از الگوریتمهای مبتنی بر روشهای آماری برای شناسایی و حذف دادههای پرت میتوان استفاده کرد (Liu et al., 2008) .
3.تفسیرپذیری مدلها
بهمنظور بهبود تفسیرپذیری مدلها، استفاده از مدلهای سادهتر مانند درختهای تصمیم یا مدلهای خطی برای مواردی که تفسیر نتایج اهمیت دارد، توصیه میشود (Ribeiro et al., 2016) .
4.بهروزرسانی و انعطافپذیری مدلها
مدلهای یادگیری ماشین باید بهطور مداوم با دادههای جدید بهروزرسانی شوند تا بتوانند تغییرات ناگهانی و غیرقابل پیشبینی را در نظر بگیرند (Pan & Yang, 2010).
مراجع:
Barocas, S., Hardt, M., & Narayanan, A. (2019). Fairness and Machine Learning. fairmlbook.org
Binns, R. (2020). On the Apparent Unfairness of Decision-Making Algorithms. Journal of Ethics in AI
Bishop, C.M. (2006). Pattern Recognition and Machine Learning. Springer
Chen, X., Han, F., & Zhou, W. (2017). Machine Learning for Stock Market Analysis. Journal of Finance
Choi, T.M., Wallace, S.W., & Wang, Y. (2018). Supply Chain Management Using Machine Learning. Production and Operations Management
Dwork, C., & Roth, A. (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theoretical Computer Science
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer
Khandani, A. E., Kim, A. J., & Lo, A. W. (2010). Consumer Credit-Risk Models. Management Science
Liu, F. T., Ting, K. M., & Zhou, Z. (2008). Isolation Forest
IEEE Transactions on Knowledge and Data Engineering
McMahan, B., Moore, E., Ramage, D., & Hampson, S. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics
Molnar, C. (2019). Interpretable Machine Learning Leanpub
Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press
Ng, A. (2018). Machine Learning Yearning. deeplearning.ai
Obermeyer, Z., Powers, B., & Vogeli, C. (2016). Applying Machine Learning in Healthcare: Insights for Policymakers. Health Economics
Pan, S. J., & Yang, Q. (2010). A Survey on Transfer Learning IEEE Transactions on Knowledge and Data Engineering
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). "Why Should I Trust You?": Explaining the Predictions of Any Classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
Russell, S., & Norvig, P. (2021). Artificial Intelligence: A Modern Approach. Pearson
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research
Stock, J. H., & Watson, M. W. (2016). Forecasting Inflation with Machine Learning. American Economic Review
Williams, C., Brown, P., & Green, J. (2020)Machine Learning Applications for Environmental Management. Environmental Science and Policy
Zemel, R., Wu, Y., Swersky, K., Pitassi, T., & Dwork, C. (2013). Learning Fair Representations International Conference on Machine Learning













